Sur les fichiers d'adresses que je vois passer depuis vingt-cinq ans, environ 10 % des lignes ont un défaut : faute de frappe, voie inexistante, code postal obsolète, complément manquant. Le chiffre vient de La Poste, et il colle à ce que j'observe sur le terrain. Pour une campagne de 50 000 plis, ce sont 5 000 enveloppes qui partent en PND (plis non distribués, dont les NPAI historiques, N'habite Pas à l'Adresse Indiquée). Coût direct : la réexpédition. Coût indirect, plus sourd : un fichier client qui se dégrade silencieusement.
La solution n'est pas mystérieuse — valider chaque adresse contre un référentiel officiel. En France, c'est la Base Adresse Nationale (BAN) qui fait référence : 26 millions d'adresses géocodées en open data, mises à jour mensuellement. Cet article décrit comment l'interroger depuis Python via l'API TrustyData : code prêt à l'emploi, schéma de réponse réel, et les pièges classiques que je vois sur les premières intégrations.
RNVP, validation postale, validation géographique : quelles différences ?
Trois notions empilées dans le même cahier des charges sans qu'on s'aperçoive qu'elles désignent trois opérations différentes. J'en ai vu les conséquences sur plusieurs projets.
La RNVP (Restructuration, Normalisation, Validation Postale)
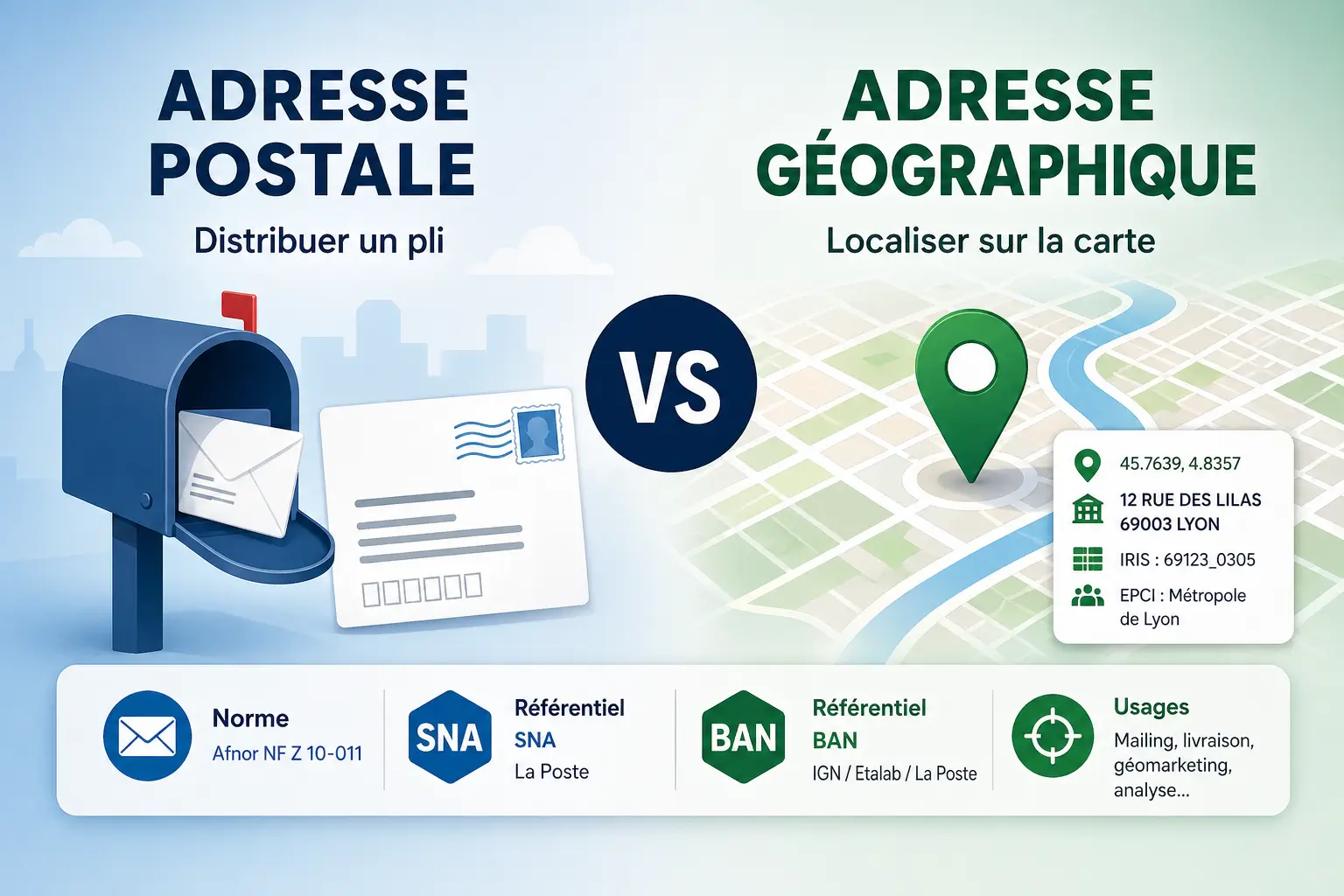
La RNVP est un procédé certifié La Poste, défini par la norme Afnor NF Z 10-011, qui s'applique à la validation postale d'un fichier en vue d'un routage courrier. Le traitement opère sur le pavé adresse complet (lignes 2 à 6 d'une enveloppe) et confronte chaque ligne au référentiel SNA (Service National de l'Adresse) de La Poste.
La RNVP enchaîne trois opérations. La restructuration éclate le pavé adresse pour isoler le numéro, le type de voie, le libellé, le code postal et la commune. La normalisation applique ensuite la norme Afnor pour obtenir un libellé conforme au standard La Poste (abréviations, casse, longueur de ligne). La validation postale confronte le résultat au référentiel SNA pour certifier la distribuabilité du courrier.
Sans RNVP, pas d'accès aux tarifs industriels de La Poste (Destineo, Postimpact). Sur un mailing de plusieurs dizaines de milliers de plis, c'est cette économie qui justifie le passage par un prestataire homologué. La RNVP inclut généralement un dédoublonnage fichier et peut débloquer une siretisation bloquée (association d'un SIRET à une adresse d'établissement) en corrigeant le pavé adresse en amont. La siretisation est un enjeu à part entière, d'autant plus depuis que le SIREN devient obligatoire sur la facture électronique : j'y consacre l'article SIREN et facturation électronique 2026.
La validation géographique (ce que fait TrustyData)
TrustyData ne réalise pas de RNVP. Son positionnement est différent et complémentaire : il s'agit de validation géographique, basée sur la Base Adresse Nationale (BAN) et le Code Officiel Géographique (COG) de l'INSEE.
Concrètement, l'API TrustyData répond à des cas d'usage différents :
| RNVP (SNA La Poste) | Validation géographique (TrustyData) | |
|---|---|---|
| Référentiel | SNA La Poste (NF Z 10-011) | BAN + COG INSEE |
| Usage principal | Routage courrier postal | Formulaires web, bases de données |
| Mode de traitement | Fichier batch | Requête unitaire temps réel |
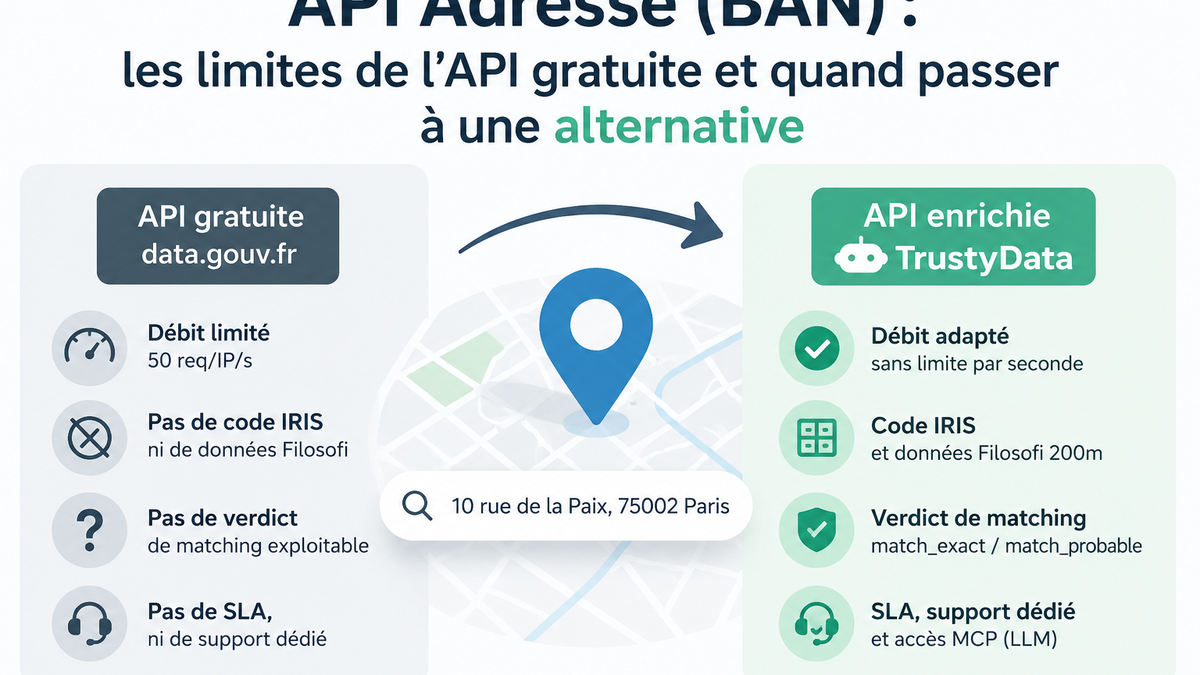
| Coordonnées GPS | Non | Oui (géocodage) |
| Codes INSEE/IRIS | Non | Oui |
| Certification La Poste | Oui | Non |
Si votre objectif est de fiabiliser la saisie d'adresse dans un formulaire, d'enrichir un fichier client avec des coordonnées GPS, des codes INSEE ou des données IRIS, ou de détecter les géocodages dégradés (adresse reconnue à la voie uniquement, sans numéro), TrustyData est l'outil adapté. Si vous avez besoin d'une certification RNVP pour votre routeur postal, orientez-vous vers un prestataire agréé SNA.
Pourquoi ne pas intégrer la BAN soi-même
La BAN est en open data, on peut la télécharger et la servir depuis sa propre infra. J'ai vu plusieurs équipes faire ce choix et le regretter au bout d'un an. Le cas typique : une ETI multi-sites monte son propre service de validation avec un ingénieur dédié. Trois ans plus tard, l'ingénieur est parti, plus personne ne sait relancer l'index quand il décroche, et les adresses entrent en base sans validation depuis des mois. Personne ne s'en aperçoit avant que les retours de courrier commencent à s'empiler.
L'ingestion initiale n'est pas le problème : quelques heures avec un script Python et un Elasticsearch ou un PostgreSQL FTS, c'est fait. La maintenance, elle, ne s'arrête jamais. La BAN sort un snapshot mensuel, les voies bougent, les communes fusionnent, les numéros se créent. Il faut une chaîne ETL qui tourne, alerter quand elle ne tourne pas, gérer les régressions d'analyseur quand vos dépendances montent de version. Côté qualité, il faut écrire et maintenir les règles de variantes de voie (AV vs AVENUE, ST vs SAINT, abréviations postales) et celles de tolérance aux fautes de frappe. C'est du travail de spécialiste, dans la même catégorie que maintenir un correcteur orthographique en interne plutôt que d'appeler une API.
Pour un projet où la qualité d'adresse n'est pas le cœur de métier, l'arbitrage est rapide : une API hostée renvoie le résultat en un appel HTTP, sans avoir à embaucher quelqu'un pour s'en occuper. C'est ce que fait l'API TrustyData. En Python avec la bibliothèque requests :
import requests
API_URL = "https://api.trustydata.app/services/v1/address/verify"
def valider_adresse(adresse: str, max_results: int = 1) -> dict:
"""Valide une adresse française via l'API TrustyData."""
response = requests.post(
API_URL,
json={"q": adresse, "max_results": max_results},
headers={"Authorization": "Bearer VOTRE_CLE_API"},
timeout=5,
)
response.raise_for_status()
return response.json()
# Exemple d'utilisation
resultat = valider_adresse("10 rue de la paix 75002 paris")
# resultat = {"status": "OK", "matches": [{verdict, score, adresse, code_insee, id_ban, position, ...}]}
for match in resultat.get("matches", []):
print(match["verdict"], match["score"], match["adresse"])
Prêt à intégrer l'API TrustyData ?
Boucler sur un fichier CSV sans saturer l'API
L'API traite une adresse par requête : il n'existe pas d'endpoint batch côté serveur. Pour enrichir un fichier complet, on boucle côté script et on parallélise les appels avec un pool de threads. C'est le pattern standard à intégrer dans un script Python ou un pipeline ETL (Airflow, Dagster, dbt…). Calibrez le max_workers selon le quota de votre plan pour ne pas saturer votre rate limit.
import csv
from concurrent.futures import ThreadPoolExecutor
def enrichir_fichier_csv(fichier_csv: str, colonne_adresse: str = "adresse"):
"""Enrichit toutes les adresses d'un fichier CSV via l'API TrustyData."""
with open(fichier_csv) as f:
lignes = list(csv.DictReader(f))
def traiter(ligne):
resultat = valider_adresse(ligne[colonne_adresse], max_results=5)
matches = resultat.get("matches") or []
top = matches[0] if matches else {}
ligne["adresse_validee"] = top.get("adresse", "")
ligne["verdict"] = top.get("verdict", "no_results")
ligne["score"] = top.get("score", 0)
ligne["code_insee"] = top.get("code_insee", "")
ligne["id_ban"] = top.get("id_ban", "")
ligne["nb_candidats"] = len(matches)
return ligne
with ThreadPoolExecutor(max_workers=10) as pool:
resultats = list(pool.map(traiter, lignes))
return resultats
L'article nettoyer un fichier d'adresses dans un pipeline Python déroule la suite : gestion d'erreurs, file de revue sur les match_probable, retry exponentiel, logging structuré.
En pratique
Valider à la saisie vaut mieux que valider après coup. Une autocomplétion BAN sur le formulaire capte le défaut avant qu'il entre en base, et évite le mauvais réflexe qui consiste à laisser passer puis « nettoyer plus tard ». Le plus tard n'arrive presque jamais.
Le moteur retourne un verdict (match_exact, match_probable, no_results) qui fait déjà le travail de tri. Inutile de recalculer un seuil sur le score brut. Les match_probable (score 0,75–0,90) doivent partir vers une file de revue manuelle plutôt que d'être rejetés : c'est là que se trouvent les saisies un peu fautives mais récupérables. Pour la précision spatiale, le bon signal est type_position : interpolation ou commune indiquent une position dégradée, parcelle ou entree sont exploitables sans contrôle. Toutes les définitions sont au glossaire.
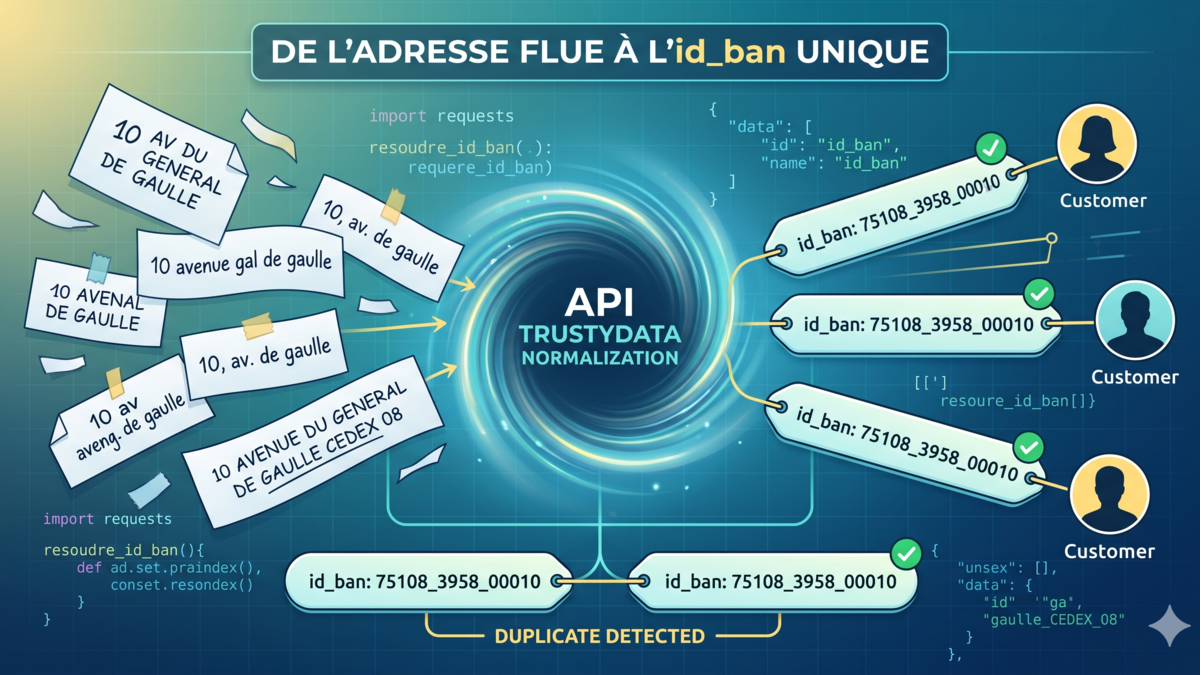
Pour dédoublonner, la clé est id_ban, l'identifiant stable retourné dans chaque match. Deux variantes de la même adresse (« 10 R DE LA PAIX » et « 10 rue de la paix, Paris 2 ») partagent le même id_ban et fusionnent proprement. La paire lat/lon n'est pas un discriminant : selon le type_position retourné, les coordonnées varient parfois de quelques mètres pour une même adresse.
La BAN bouge : voies créées, communes fusionnées, numéros ajoutés. Une base validée il y a un an n'est plus fiable. Revalidation mensuelle ou trimestrielle selon la criticité.
Côté débit, calez le parallélisme sur le quota de votre plan. Le max_workers=10 de l'exemple ci-dessus n'a pas le même sens sur Discovery (5 000 req/mois) que sur Business. Sur l'autocomplétion en formulaire, un debounce de 200 ms suffit à protéger l'API des frappes rapides. Et si vos données viennent de sources hétérogènes (CRM, ERP, import manuel), nettoyez les champs avant l'appel API : vous gagnez en taux de correspondance et en quota.
Pour résumer
La BAN couvre les besoins de validation géographique : vérifier qu'une adresse existe, récupérer ses coordonnées GPS et son code INSEE, remonter à l'IRIS. C'est ce que TrustyData expose en API. Quelques lignes de Python suffisent à fiabiliser une saisie de formulaire ou à enrichir un fichier client au fil de l'eau. Si vous partez de l'API Adresse officielle de data.gouv.fr et cherchez à en cerner les limites avant de passer à une API dédiée, l'article les limites de l'API Adresse gratuite et quand envisager une alternative détaille les différences et les critères de choix.
Ce que la BAN ne fait pas, c'est de la certification RNVP au sens de la norme Afnor NF Z 10-011. Pour un routage postal industriel (tarifs Destineo, dédoublonnage SNA, lignes de 38 caractères, gestion des CEDEX), il faut un prestataire homologué La Poste. J'en parle en détail dans l'article référentiels RNVP et validation postale. Les deux outils sont complémentaires, pas concurrents.
Le plan Discovery donne 5 000 requêtes par mois gratuites, sans carte bancaire, sur la page tarifs.