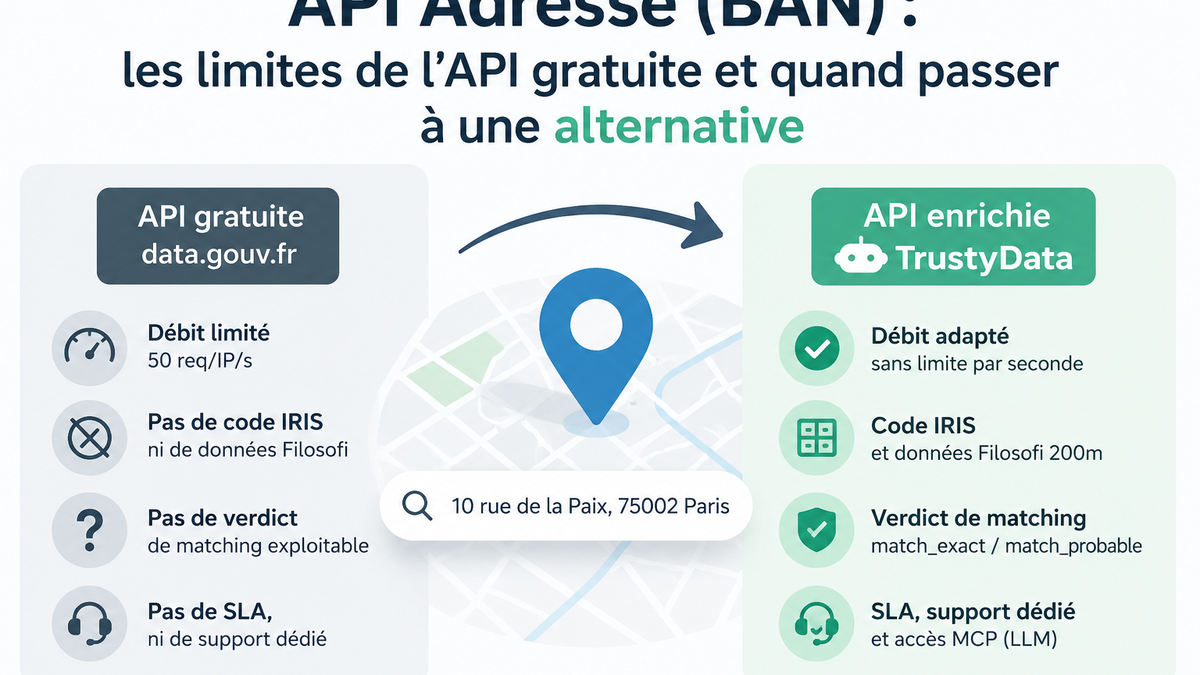
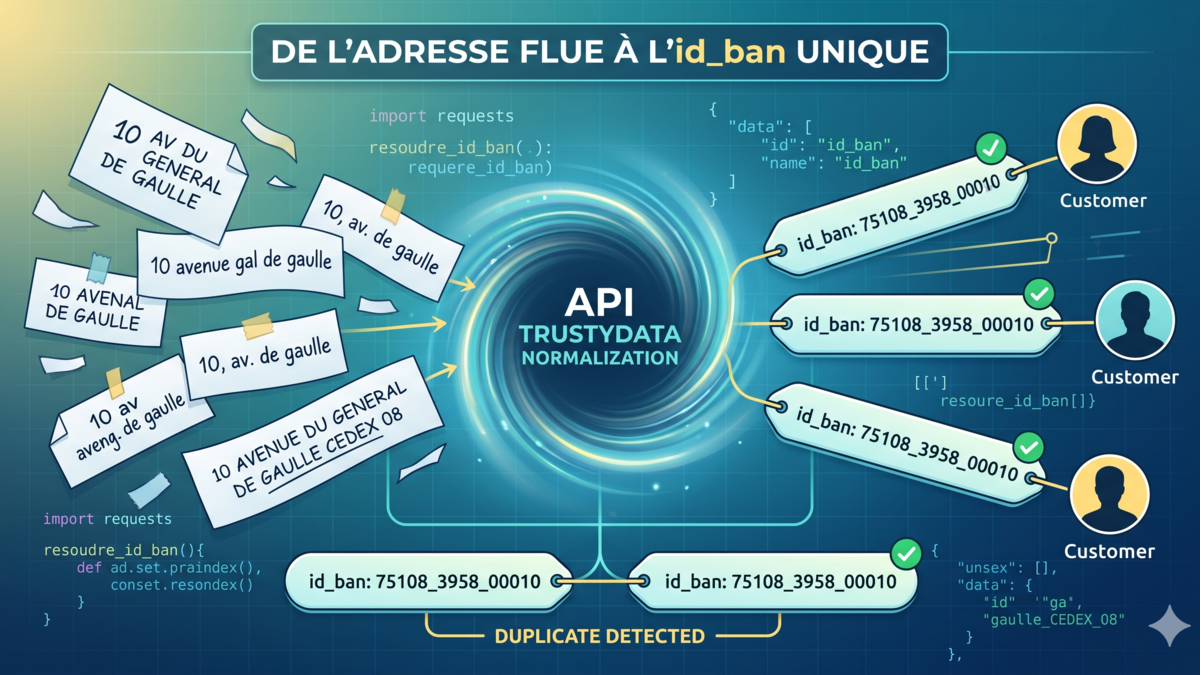
Votre base CRM compte 50 000 enregistrements. Certains ont été importés depuis un fichier Excel, d'autres saisis manuellement par des commerciaux, d'autres encore migrés depuis un ancien système. Résultat : "av." et "avenue" cohabitent pour la même voie, des codes postaux ont perdu le premier 0 ou ont pris une notation scientifique, des communes ont fusionné depuis la saisie initiale. Comparer ces adresses brutes entre elles ne donne rien, les doublons passent à travers, le géocodage échoue.
Le problème n'est pas de valider des adresses à la saisie. C'est de traiter une base qui existe déjà. C'est un problème d'ETL, pas de formulaire. La différence entre le préventif et le curatif. Le nettoyage de la donnée s'applique aussi sur le stock.
Pourquoi la déduplication et le géocodage échouent sur des adresses brutes
Une adresse non normalisée est une chaîne de caractères libre. Deux enregistrements pour le même lieu peuvent s'écrire de dizaines de façons différentes :
10 avenue du Général de Gaulle
10 av gal de gaulle
10 Av. Général DeGaulle
10, avenue du général-de-gaulle
Aucun algorithme de comparaison de chaînes, même avec une distance de Levenshtein, ne rapprochera ces quatre variantes de manière fiable à l'échelle. Sans oublier que parfois les différences peuvent être plus importantes. Général de Gaulle ou Maréchal de Gaulle ? La seule approche robuste : passer chaque adresse par un référentiel officiel pour obtenir une forme canonique identique, puis comparer les formes canoniques.
C'est exactement ce que fait la vérification d'adresse via la Base Adresse Nationale. Elle vous aide à rendre les choses comparables. Il n'est pas forcément nécessaire de normaliser les adresses dans les règles de l'art pour faire une déduplication, les adresses de la BAN sont suffisantes pour rendre les informations homogènes donc comparables.
Architecture du pipeline
Un pipeline de nettoyage de données et d'adresses suit systématiquement la même logique, intégrant des étapes de prétraitement des données pour assurer la qualité et la précision des résultats :
/v1/address/verifyverdictmatch_exactcandidat unique
match_probableou plusieurs candidats
no_resultsLe pipeline ne tranche pas sur un seuil de score arbitraire. Il s'appuie sur le verdict que l'API a déjà calculé. Un seul candidat avec le verdict match_exact : la mise à jour est sûre. Plusieurs candidats, ou un verdict match_probable : l'arbitrage revient à un opérateur. Liste vide : l'adresse est rejetée. La suite explique comment l'API construit ce verdict.
Comment l'API calcule le verdict
L'API ne se contente pas de retourner les meilleures correspondances de la BAN. Elle exécute trois étapes successives qui produisent une réponse exploitable directement, sans manipuler le score à la main.
Étape 1 — Le verdict d'identité de l'analyseur
Pour chaque adresse candidate, un analyseur NLP compare la requête au candidat et émet un verdict :
| Verdict API | Signification |
|---|---|
match_exact |
Le candidat est très probablement la même adresse que la requête. |
match_probable |
Le candidat est plausiblement la même adresse, mais avec un doute (numéro absent, abréviation ambiguë, fragment manquant). |
Le verdict ne se déduit pas du score seul. C'est l'analyseur qui décide, en regardant la cohérence sémantique entre la requête et le candidat : numéro présent ou non, voie reconnue, code postal compatible, commune correcte.
Étape 2 — Filtrage hiérarchique
L'API applique ensuite une priorité stricte sur la liste des candidats :
- S'il existe au moins un
match_exact→ seuls lesmatch_exactsont conservés. Tous lesmatch_probable, même très bien notés, sont écartés. - Sinon, s'il existe au moins un
match_probable→ seuls lesmatch_probablesont conservés. - Sinon → la réponse est
no_results(liste vide).
Conséquence pratique : tous les candidats d'une même réponse portent le même verdict. Vous n'avez jamais à arbitrer entre un exact et un probable dans la même liste.
Note : un troisième verdict
aucun_matchexiste dans la spec mais n'est jamais retourné. Quand aucun candidat ne passe les filtres, l'API renvoie un statutno_resultsavec une liste vide. Le test côté client est donc binaire : la liste est vide, ou elle contient des candidats du même verdict.
Étape 3 — Score gap : on coupe au premier décrochage
Une fois la liste filtrée et triée par score décroissant, l'API ne renvoie pas mécaniquement les N meilleurs candidats : elle coupe dès qu'un écart consécutif entre deux scores dépasse un seuil.
| Condition sur le 1ᵉʳ score | Seuil de coupure |
|---|---|
score₀ ≥ 0,999 (match quasi-parfait) |
0,02 (strict) |
score₀ < 0,999 |
0,04 (standard) |
Prenons une liste de scores triés : [0.92, 0.90, 0.87, 0.80, 0.79].
- 0,92 − 0,90 = 0,02 → ≤ 0,04 → on garde.
- 0,90 − 0,87 = 0,03 → ≤ 0,04 → on garde.
- 0,87 − 0,80 = 0,07 → > 0,04 → coupure.
Réponse renvoyée : [0.92, 0.90, 0.87]. Les candidats à 0,80 et 0,79 sont écartés, même si leur score absolu reste correct ; ils appartiennent à un palier de confiance inférieur. Pour un match quasi-parfait (score₀ ≥ 0,999), le seuil tombe à 0,02 : un seul candidat très proche de la perfection prévaut sur une liste tiède.
Comment l'utiliser dans votre pipeline
Trois cas suffisent à couvrir 100 % des réponses :
| Cas reçu | Décision pipeline |
|---|---|
Liste vide (no_results) |
Aucune correspondance fiable → file de rejet, alerter l'opérateur. |
verdict = match_exact et un seul candidat |
Mise à jour automatique fiable. |
verdict = match_exact avec plusieurs candidats, ou verdict = match_probable |
Ambiguïté ou doute → file de revue manuelle. |
Vous n'avez plus à comparer le score à des seuils choisis arbitrairement : l'API a déjà fait le travail. Le score reste utile pour ordonner la file de revue (présenter les cas les plus probables en premier) et pour repérer les dérives dans le temps, mais pas pour décider du tri automatique.
À quoi ressemble une réponse en pratique
Voici les trois formes de réponse que vous rencontrerez réellement sur /address/verify.
Cas 1, match_exact à candidat unique → mise à jour automatique.
Requête : q = "10 av gal de gaulle 92800 puteaux"
{
"status": "OK",
"matches": [
{
"verdict": "match_exact",
"score": 0.97,
"adresse": "10 Avenue du Général de Gaulle 92800 Puteaux",
"code_postal": "92800",
"nom_commune": "Puteaux",
"code_insee": "92062",
"id_ban": "92062_3700_00010",
"position": { "lat": 48.8847, "lon": 2.2378 },
"geocoding": { "code_iris": "920620301" }
}
]
}
L'analyseur a identifié un seul candidat match_exact. Le score gap n'a rien à filtrer (un seul élément). Côté pipeline : len(matches) == 1 et verdict == "match_exact" → status = "ok".
Cas 2, match_exact à plusieurs candidats équivalents → file de revue.
Requête : q = "5 rue de la paix" (ni code postal, ni commune fournis).
{
"status": "OK",
"matches": [
{
"verdict": "match_exact",
"score": 0.91,
"adresse": "5 Rue de la Paix 75002 Paris",
"code_insee": "75102",
"id_ban": "75102_7203_00005",
"position": { "lat": 48.8694, "lon": 2.3318 }
},
{
"verdict": "match_exact",
"score": 0.90,
"adresse": "5 Rue de la Paix 92500 Rueil-Malmaison",
"code_insee": "92063",
"id_ban": "92063_7203_00005",
"position": { "lat": 48.8783, "lon": 2.1814 }
},
{
"verdict": "match_exact",
"score": 0.89,
"adresse": "5 Rue de la Paix 93140 Bondy",
"code_insee": "93010",
"id_ban": "93010_7203_00005",
"position": { "lat": 48.9015, "lon": 2.4828 }
}
]
}
Trois candidats match_exact, scores resserrés (gap 0,01 et 0,01, sous le seuil 0,04 → tous conservés). L'analyseur considère que les trois adresses sont des correspondances valides à la requête tronquée. Il faut un opérateur pour départager. Côté pipeline : len(matches) > 1 → status = "review", et la liste complète des candidats part dans la file de revue (voir section Préparer la file de revue manuelle plus bas).
Cas 3, no_results → rejet / alerte.
Requête : q = "12 rue inexistante 99999 nullepart"
{
"status": "no_results",
"matches": []
}
Aucun candidat n'a passé le filtrage hiérarchique. Côté pipeline : matches vide → status = "rejected".
Prêt à intégrer l'API TrustyData ?
Implémentation Python
Structure de base
import requests
import pandas as pd
from dataclasses import dataclass, field
from typing import Optional
API_KEY = "votre_clé_api"
BASE_URL = "https://api.trustydata.app/services/v1/address/verify"
@dataclass
class AddressResult:
raw: str
normalized: Optional[str] = None
verdict: Optional[str] = None # "match_exact" | "match_probable" | None
score: Optional[float] = None
candidates_count: int = 0
lat: Optional[float] = None
lon: Optional[float] = None
code_insee: Optional[str] = None
iris: Optional[str] = None
id_ban: Optional[str] = None
# Candidats alternatifs (rang 2..N) à présenter en revue manuelle.
alternatives: list = field(default_factory=list)
status: str = "pending" # "ok" | "review" | "rejected" | "error"
def _slim(match: dict) -> dict:
"""Représentation compacte d'un candidat pour la file de revue."""
pos = match.get("position") or {}
return {
"adresse": match.get("adresse"),
"score": match.get("score"),
"code_insee": match.get("code_insee"),
"id_ban": match.get("id_ban"),
"lat": pos.get("lat"),
"lon": pos.get("lon"),
}
def verify_address(raw: str) -> AddressResult:
result = AddressResult(raw=raw)
try:
r = requests.post(
BASE_URL,
json={"q": raw, "max_results": 5},
headers={"Authorization": f"Bearer {API_KEY}"},
timeout=5,
)
r.raise_for_status()
data = r.json()
matches = data.get("matches") or []
# Liste vide → no_results, rien à exploiter.
if not matches:
result.status = "rejected"
return result
best = matches[0]
result.verdict = best.get("verdict")
result.candidates_count = len(matches)
result.normalized = best.get("adresse")
result.score = best.get("score")
pos = best.get("position") or {}
result.lat = pos.get("lat")
result.lon = pos.get("lon")
result.code_insee = best.get("code_insee")
result.iris = (best.get("geocoding") or {}).get("code_iris")
result.id_ban = best.get("id_ban")
# On garde les alternatives (rang 2..N) pour la revue manuelle.
result.alternatives = [_slim(m) for m in matches[1:]]
# Décision pilotée par le verdict + le nombre de candidats.
# Cf. section "Comment l'API calcule le verdict".
if result.verdict == "match_exact" and result.candidates_count == 1:
result.status = "ok"
else:
# match_probable, ou match_exact avec plusieurs candidats équivalents.
result.status = "review"
except requests.RequestException:
result.status = "error"
return result
Robustesse en production : retry, rate-limit, timeout
La version ci-dessus suffit pour valider une centaine d'adresses depuis un notebook. Sur 50 000 lignes en parallèle, trois choses finissent toujours par arriver : un timeout réseau ponctuel, un 429 Too Many Requests quand vous tapez la limite du plan, ou un 503 transitoire côté serveur. Sans retry, chacun de ces incidents transforme une ligne pourtant valide en status = "error".
Trois règles suffisent pour rendre le script utilisable en production :
- Réessayer ce qui est temporaire (
429,5xx,Timeout,ConnectionError) avec un back-off exponentiel. - Ne pas réessayer ce qui est définitif (
400requête malformée,401clé API,403). Réessayer ne corrigera pas une erreur métier. - Respecter le header
Retry-Afterquand l'API en renvoie un sur429: c'est le temps à attendre avant la prochaine tentative.
# pip install tenacity
import logging
import time
import requests
from tenacity import (
retry,
retry_if_exception_type,
stop_after_attempt,
wait_exponential,
)
logger = logging.getLogger(__name__)
class _RetryableHTTPError(Exception):
"""Erreur HTTP temporaire (429 ou 5xx) — réessayable."""
@retry(
retry=retry_if_exception_type((
requests.Timeout,
requests.ConnectionError,
_RetryableHTTPError,
)),
stop=stop_after_attempt(5),
wait=wait_exponential(multiplier=1, min=1, max=30),
reraise=True,
)
def _call_verify(payload: dict) -> dict:
r = requests.post(
BASE_URL,
json=payload,
headers={"Authorization": f"Bearer {API_KEY}"},
timeout=10,
)
if r.status_code == 429:
# Respecter Retry-After si fourni, sinon laisser tenacity gérer
# le back-off exponentiel défini ci-dessus.
retry_after = r.headers.get("Retry-After")
if retry_after and retry_after.isdigit():
time.sleep(int(retry_after))
raise _RetryableHTTPError("HTTP 429 rate-limited")
if 500 <= r.status_code < 600:
raise _RetryableHTTPError(f"HTTP {r.status_code} server error")
r.raise_for_status() # Les autres 4xx remontent sans retry.
return r.json()
La fonction verify_address ne change quasiment pas : elle délègue désormais l'appel HTTP au wrapper.
def verify_address(raw: str) -> AddressResult:
result = AddressResult(raw=raw)
try:
data = _call_verify({"q": raw, "max_results": 5})
except requests.HTTPError as exc:
# 4xx définitif (clé invalide, requête malformée…).
logger.warning("Erreur définitive sur '%s' : %s", raw, exc)
result.status = "error"
return result
except (requests.RequestException, _RetryableHTTPError) as exc:
# Les 5 tentatives ont échoué. On marque error et on continue.
logger.warning("Échec après retry sur '%s' : %s", raw, exc)
result.status = "error"
return result
# Reste du parsing identique à la version simple : matches, verdict, etc.
matches = data.get("matches") or []
if not matches:
result.status = "rejected"
return result
# … (cf. version simple ci-dessus)
return result
Calibrer max_workers sur le rate-limit du plan. Chaque plan a une limite (par exemple 100 req/s sur Growth, 500 req/s sur Business). Si vous lancez 50 workers parallèles sur un plan limité à 100 req/s, vous allez taper le 429 en boucle. Le retry règle l'incident, mais gaspille du temps. Comptez max_workers ≈ rate_limit_par_seconde × temps_de_réponse_moyen. Avec 100 req/s et ~100 ms par appel, 10 workers saturent confortablement le quota sans le dépasser.
Sur des bases très volumineuses (> 100 k lignes), prévoyez une persistance intermédiaire : sauvegardez les résultats par lots de 1 000 ou 5 000 lignes (parquet ou CSV append), avec une clé d'idempotence sur le hash de l'adresse brute. Si le pipeline tombe à 30 000 lignes, vous reprenez où vous étiez plutôt que de tout rejouer.
Traitement d'un DataFrame avec parallélisation
Pour une base de plusieurs milliers de lignes, la parallélisation réduit le temps de traitement proportionnellement au nombre de workers. Avec 10 workers et une API qui répond en ~100 ms, vous traitez ~100 adresses/seconde.
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm # pip install tqdm
def process_dataframe(
df: pd.DataFrame,
address_col: str,
max_workers: int = 10,
) -> pd.DataFrame:
"""
Vérifie et normalise toutes les adresses d'un DataFrame.
Ajoute les colonnes : adresse_normalisee, verdict, score_verification,
nb_candidats, lat, lon, code_insee, code_iris, id_ban, alternatives,
statut_verification.
"""
results = {}
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {
executor.submit(verify_address, row[address_col]): idx
for idx, row in df.iterrows()
}
for future in tqdm(as_completed(futures), total=len(futures)):
idx = futures[future]
results[idx] = future.result()
df["adresse_normalisee"] = [results[i].normalized for i in df.index]
df["verdict"] = [results[i].verdict for i in df.index]
df["score_verification"] = [results[i].score for i in df.index]
df["nb_candidats"] = [results[i].candidates_count for i in df.index]
df["lat"] = [results[i].lat for i in df.index]
df["lon"] = [results[i].lon for i in df.index]
df["code_insee"] = [results[i].code_insee for i in df.index]
df["code_iris"] = [results[i].iris for i in df.index]
df["id_ban"] = [results[i].id_ban for i in df.index]
df["alternatives"] = [results[i].alternatives for i in df.index]
df["statut_verification"] = [results[i].status for i in df.index]
return df
Exploitation des résultats
# Chargement
df = pd.read_csv("clients.csv")
# Préparation : concaténer les champs si adresse éclatée en colonnes
df["adresse_complete"] = (
df["numero"].fillna("") + " "
+ df["voie"].fillna("") + " "
+ df["code_postal"].fillna("") + " "
+ df["commune"].fillna("")
).str.strip()
# Traitement
df = process_dataframe(df, address_col="adresse_complete")
# Tri par statut
ok = df[df["statut_verification"] == "ok"]
to_review = df[df["statut_verification"] == "review"]
rejected = df[df["statut_verification"] == "rejected"]
print(f"Mise à jour automatique : {len(ok)} ({len(ok)/len(df)*100:.1f}%)")
print(f"À revoir manuellement : {len(to_review)} ({len(to_review)/len(df)*100:.1f}%)")
print(f"Non résolus : {len(rejected)} ({len(rejected)/len(df)*100:.1f}%)")
# Export
ok.to_csv("clients_valides.csv", index=False)
to_review.to_csv("clients_a_revoir.csv", index=False)
rejected.to_csv("clients_rejetes.csv", index=False)
Préparer la file de revue manuelle
Quand statut_verification == "review", l'opérateur a besoin de tous les candidats équivalents retournés par l'API, pas seulement du meilleur. C'est ce que stocke la colonne alternatives : la liste des candidats de rang 2 à N. Pour produire un fichier exploitable dans un outil de revue, on aplatit en une ligne par candidat.
to_review = df[df["statut_verification"] == "review"].copy()
def _build_candidates(row) -> list[dict]:
"""Liste tous les candidats du verdict gagnant, rang 1 = meilleur."""
head = {
"rang": 1,
"adresse": row["adresse_normalisee"],
"score": row["score_verification"],
"code_insee": row["code_insee"],
"id_ban": row["id_ban"],
"lat": row["lat"],
"lon": row["lon"],
}
tail = [
{"rang": i + 2, **alt}
for i, alt in enumerate(row["alternatives"] or [])
]
return [head] + tail
to_review["candidats"] = to_review.apply(_build_candidates, axis=1)
# Une ligne par candidat à départager — format consommable par un outil
# de back-office (Retool, Airtable, mini-app Streamlit, etc.).
review_long = (
to_review[["adresse_complete", "verdict", "nb_candidats", "candidats"]]
.explode("candidats")
)
review_long = pd.concat(
[
review_long.drop(columns=["candidats"]).reset_index(drop=True),
pd.json_normalize(review_long["candidats"]).reset_index(drop=True),
],
axis=1,
)
review_long.to_csv("file_de_revue.csv", index=False)
Le CSV obtenu contient une ligne par couple (adresse brute × candidat), avec un rang qui ordonne les candidats par score décroissant. L'opérateur n'a qu'à cocher le bon id_ban pour chaque adresse brute. Une fois la décision prise, vous remontez l'id_ban choisi dans la base source. La mise à jour devient idempotente, exactement comme pour les match_exact à candidat unique.
Astuce : pour les
match_probableà candidat unique, présentez quand même à l'opérateur l'adresse brute à côté de l'adresse normalisée. Le doute porte sur l'identité (numéro absent, abréviation ambiguë), pas sur le choix entre plusieurs voies. Une simple validation oui/non suffit.
Dédupliquer après normalisation
Une fois les adresses normalisées, la déduplication devient fiable. L'identifiant BAN (id_ban) retourné dans la réponse est le plus robuste : deux adresses identiques dans le référentiel ont le même id_ban, quelles que soient leurs variantes originales.
# Déduplication sur l'identifiant BAN — clé canonique pour deux
# enregistrements pointant vers la même adresse, quelles que soient
# les variantes d'écriture en entrée.
ok = df[df["statut_verification"] == "ok"]
doublons = ok.duplicated(subset=["id_ban"], keep="first")
print(f"Doublons détectés après normalisation : {doublons.sum()}")
df_dedup = ok[~doublons]
À défaut de l'id_ban, l'adresse normalisée fait un bon proxy de déduplication. Elle est produite par le même référentiel pour tous les enregistrements.
Enrichissement automatique en sortie
Ce pipeline ne fait pas que corriger les adresses. Chaque enregistrement résolu ressort enrichi avec :
- Coordonnées GPS (WGS84) : utilisables directement pour l'affichage cartographique ou le calcul de zone de chalandise
- Code INSEE commune : pour les jointures avec des référentiels INSEE, les agrégations par territoire
- Code IRIS : le découpage statistique infra-communal de l'INSEE, utile pour croiser avec les données socio-démographiques Filosofi
- Code Carreau : le découpage statistique de 200 m, le maillage le plus précis pour vos statistiques.
C'est le principal avantage d'une API qui s'appuie sur la BAN et l'INSEE simultanément : la correction de l'adresse et l'enrichissement géographique sont produits dans le même appel.
Points d'attention
Concaténer les champs avant l'appel. Si votre base stocke le numéro, la voie, le code postal et la commune dans des colonnes séparées, concaténez-les en une seule chaîne avant l'appel API. L'algorithme de matching de la BAN est plus efficace sur une chaîne libre que sur des champs structurés fournis séparément.
Gérer les adresses CEDEX. Les codes CEDEX ne figurent pas dans la BAN. Si votre base contient des adresses professionnelles avec CEDEX, filtrez-les en amont ou traitez-les séparément. Elles reviendront systématiquement avec un score bas.
Privilégier le verdict, garder le score pour la priorisation. La décision automatique doit s'appuyer sur verdict + nombre de candidats. C'est le travail que l'API a déjà fait. Le score reste utile pour ordonner la file de revue manuelle (cas les plus probables en haut, les plus douteux en bas) et pour repérer les dérives dans le temps : un score moyen qui baisse signale une base qui vieillit. Sur un cas particulièrement sensible (souscription, livraison à valeur élevée), vous pouvez ajouter une règle métier qui bascule un match_exact à candidat unique en revue si son score est inférieur à un seuil que vous fixez.
Revalider périodiquement. La BAN est mise à jour en continu. Des communes fusionnent, des voies sont renommées. Une adresse validée en 2022 peut retourner un score dégradé aujourd'hui. Intégrez une date de dernière vérification dans votre modèle de données et revalidez les enregistrements anciens.
Ce que ce pipeline ne remplace pas
Ce pipeline produit une validation géographique d'adresse basée sur la Base Adresse Nationale. Il vérifie qu'une adresse est présente dans le référentiel BAN officiel (IGN) et retourne sa forme normalisée avec coordonnées GPS et identifiants statistiques. Si votre objectif final est un fichier postal routé pour une campagne de mailing physique, c'est une étape de préparation utile pour fiabiliser la base en amont, mais il faudra ensuite passer par un prestataire spécialisé dans le routage postal.
Pour aller plus loin
L'API retourne également les données du carroyage INSEE à 200 mètres pour chaque adresse résolue (plan Business) : revenus médians, structure des ménages, parc de logements. Dans un pipeline CRM, cela permet de scorer chaque client selon le profil socio-démographique de son adresse, sans aucune donnée personnelle supplémentaire à collecter.
➜ Découvrir le use case vérification d'adresses
➜ Enrichissement statistique IRIS et carroyage INSEE
TrustyData est une API REST de qualité de données pour les adresses françaises, construite sur la Base Adresse Nationale et les référentiels INSEE. Plan Discovery gratuit : 5 000 requêtes/mois, sans carte bancaire.