Le cas type que je vois tous les ans : une équipe CRM lance une dédup sur la base client, compare les adresses avec une distance de Levenshtein et un seuil, fusionne ce qui se ressemble. Six mois plus tard, le service client reçoit des appels de gens qui ne reçoivent plus rien, ou qui reçoivent le courrier d'un autre. Quelques fusions abusives suffisent à plomber la confiance dans le fichier pendant un an. À l'inverse, jouer la dédup trop conservatrice laisse passer des doublons évidents pour un humain mais invisibles pour un algorithme de chaînes.
Une précision avant le code : on ne dédoublonne pas des adresses, on dédoublonne des personnes physiques ou des personnes morales. L'adresse est un attribut parmi d'autres (nom, prénom, date de naissance, raison sociale, SIRET) et la clé de dédup est toujours composite. Si je consacre un article entier à cette seule composante, c'est qu'elle est presque toujours celle qui fait planter l'opération : les autres champs bougent peu, l'adresse est volatile et casse les algos naïfs.
Pour la rendre comparable, on s'appuie sur l'identifiant que la Base Adresse Nationale attribue à chaque point d'adresse, l'id_ban. Deux saisies du même point partagent le même id_ban après validation, ce qui ramène la composante adresse à une égalité stricte sur un identifiant stable.
Pourquoi ni la chaîne ni les coordonnées ne font un bon composant adresse
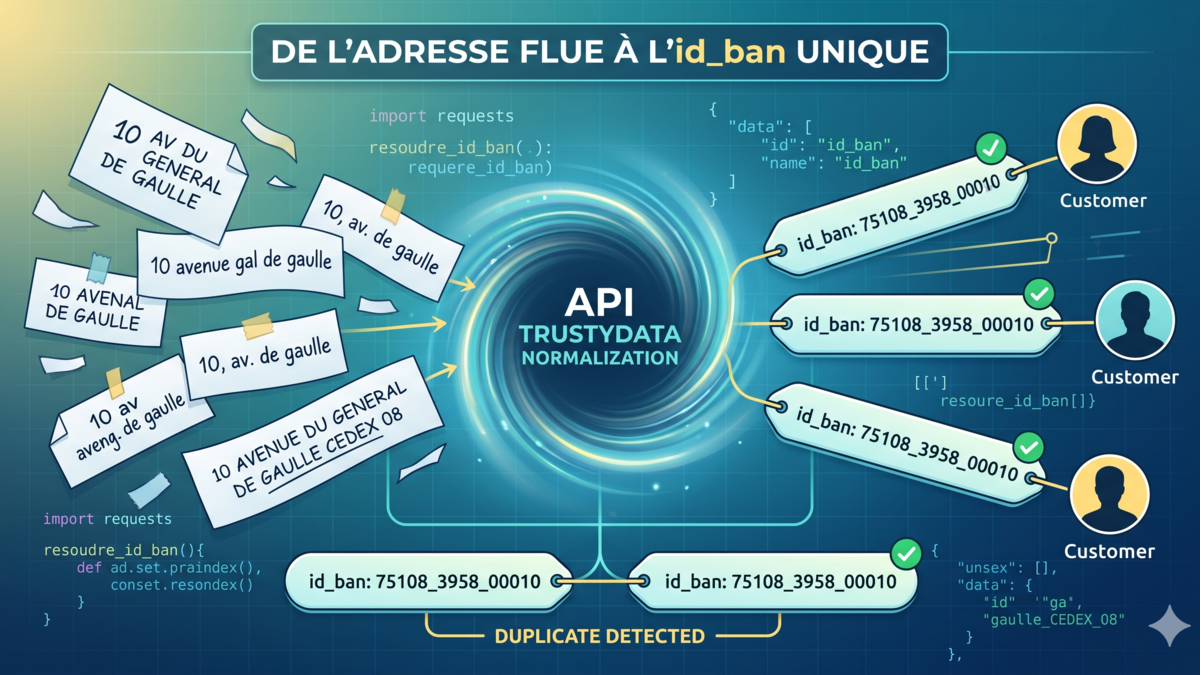
La chaîne d'adresse libre est tout sauf canonique. Quatre saisies pour le même point :
10 avenue du Général de Gaulle, 75008 Paris
10 av. gal de gaulle 75008
10, Av Général-De-Gaulle, Paris 8e
10 AVENUE DU GENERAL DE GAULLE 75008 PARIS CEDEX 08
Une distance de Levenshtein à 5 caractères rapproche les deux premières, écarte la troisième, et confond la quatrième avec une adresse CEDEX différente. Un seuil plus large rattrape la troisième mais commence à fusionner des choses qui n'ont rien à voir (« 10 rue de Gaulle » à Lille). Aucun seuil universel n'existe sur un fichier hétérogène.
Le couple latitude/longitude semble plus rigoureux mais n'est pas un discriminant fiable non plus. Selon le type_position retourné par la BAN, la position d'un même point d'adresse peut varier de quelques mètres entre deux interrogations ou deux millésimes : centroïde de parcelle, entrée de bâtiment, interpolation sur la voie. Deux enregistrements pour le 10 avenue du Général de Gaulle peuvent ressortir à 49,1234 / 2,1234 dans l'un et 49,1235 / 2,1235 dans l'autre. Une comparaison sur (lat, lon) les sépare, un arrondi mal choisi en fusionne d'autres qui sont voisins mais distincts.
Le id_ban est l'identifiant que l'IGN attribue à chaque point d'adresse de la BAN. Il reste stable entre deux millésimes tant que la voie n'est pas renommée, ce qui permet de le persister en base sans le recalculer à chaque passage de validation.
Récupérer le id_ban en Python
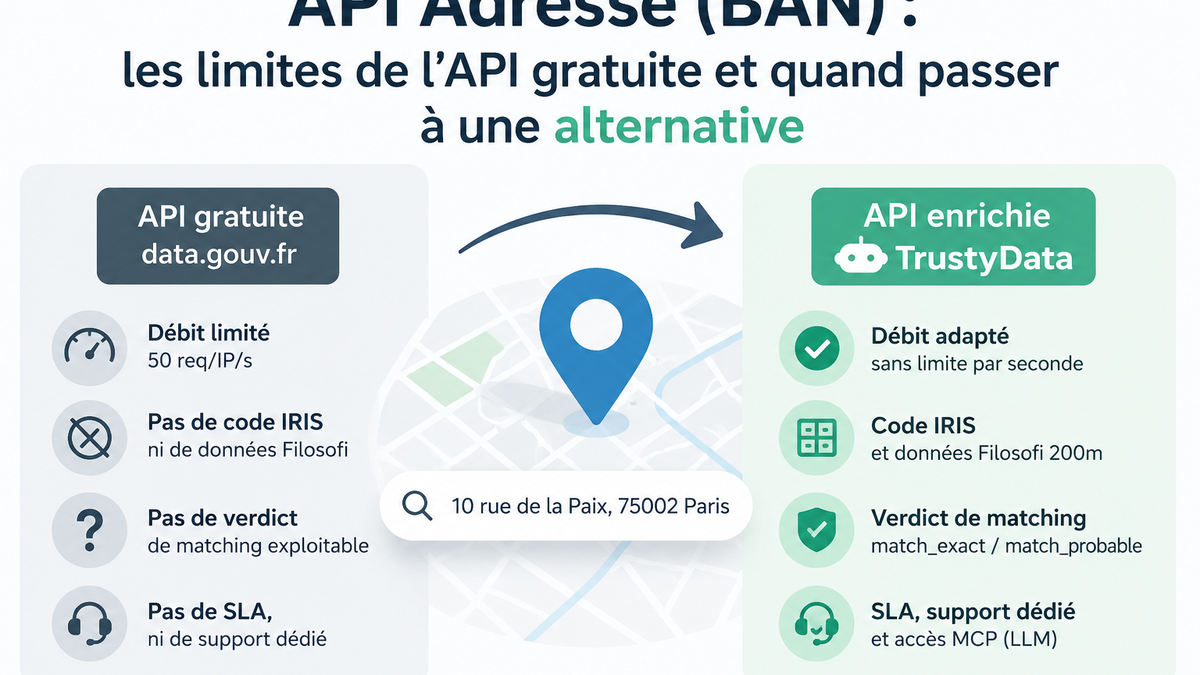
L'endpoint est POST /address/verify. Le champ id_ban est exposé dès le plan Discovery, donc disponible sur l'offre gratuite. Pour la dédup pure, on passe details=false et on économise le payload : seuls id_ban, adresse, verdict et score reviennent.
import requests
API_URL = "https://api.trustydata.app/services/v1/address/verify"
HEADERS = {"Authorization": "Bearer VOTRE_CLE_API"}
def resoudre_id_ban(adresse: str) -> dict:
"""Retourne id_ban + verdict pour une adresse, ou un statut explicite."""
response = requests.post(
API_URL,
json={"q": adresse, "max_results": 5, "details": False},
headers=HEADERS,
timeout=5,
)
response.raise_for_status()
matches = response.json().get("matches") or []
if not matches:
return {"id_ban": None, "verdict": "no_results", "candidats": 0}
top = matches[0]
return {
"id_ban": top["id_ban"],
"adresse_canonique": top["adresse"],
"verdict": top["verdict"], # "match_exact" ou "match_probable"
"score": top["score"],
"candidats": len(matches),
}
print(resoudre_id_ban("10 av. gal de gaulle 75008"))
# {'id_ban': '75108_3958_00010', 'adresse_canonique': '10 Avenue du Général de Gaulle, 75008 Paris',
# 'verdict': 'match_exact', 'score': 0.97, 'candidats': 1}
Pour un fichier complet, on boucle avec un pool de threads calibré sur le quota du plan. Le pattern est détaillé dans normaliser une adresse française en Python : ThreadPoolExecutor, 10 workers parallèles sur Growth, retry exponentiel sur 5xx, persistance des résultats au fur et à mesure pour pouvoir reprendre.
Prêt à intégrer l'API TrustyData ?
La clé de dédup composite, et la fusion derrière
Une fois le id_ban posé sur chaque ligne, le groupby ne porte pas dessus seul. La clé composite dépend du type de fichier. Pour du B2C, c'est typiquement id_ban + nom_normalisé + prenom_normalisé, avec un complément quand l'habitat collectif est en jeu (j'y reviens dans la section pièges). Pour du B2B, c'est id_ban + raison_sociale_normalisée, ou id_ban + SIRET si le SIRET est fiable côté source. Ce « si » n'a rien d'évident : fiabiliser le SIREN et le SIRET est un sujet à part entière, que je traite dans SIREN et facturation électronique 2026.
Le squelette du code en pandas :
import pandas as pd
import unicodedata
# df contient les colonnes : id_client, id_ban, adresse_canonique, verdict,
# nom, prenom, email, telephone, date_modification,
# complement_adresse, ...
def normaliser_texte(s: str) -> str:
"""Casse, accents, espaces : prépare le champ pour la comparaison."""
if not isinstance(s, str):
return ""
s = unicodedata.normalize("NFKD", s).encode("ascii", "ignore").decode()
return " ".join(s.upper().split())
# 1) On ne dédoublonne que les match_exact, jamais les match_probable
auto = df[df["verdict"] == "match_exact"].copy()
revue = df[df["verdict"] == "match_probable"].copy()
rejet = df[df["verdict"] == "no_results"].copy()
# 2) Construction de la clé composite (ici un B2C particulier)
auto["nom_n"] = auto["nom"].map(normaliser_texte)
auto["prenom_n"] = auto["prenom"].map(normaliser_texte)
cle_dedup = ["id_ban", "nom_n", "prenom_n"]
# 3) Groupement et choix de la ligne canonique
def fusionner_groupe(g: pd.DataFrame) -> pd.Series:
# Le plus récent gagne sur les champs volatils (email, téléphone)
g = g.sort_values("date_modification", ascending=False)
canonique = g.iloc[0].copy()
# Le complément le plus informatif gagne (BAT, ESC, APPT...)
complements = g["complement_adresse"].dropna().astype(str)
if len(complements) > 0:
canonique["complement_adresse"] = complements.loc[complements.str.len().idxmax()]
# On trace la fusion pour pouvoir l'auditer
canonique["fusion_ids"] = ",".join(map(str, g["id_client"].tolist()))
canonique["fusion_count"] = len(g)
return canonique
canonical = auto.groupby(cle_dedup, as_index=False).apply(fusionner_groupe)
La normalisation des champs d'identité (normaliser_texte) avant le groupby compte autant que celle de l'adresse. Sans elle, « Tristram » et « TRISTRAM » créent deux groupes. Sur des populations plus larges, prévoyez aussi la gestion des particules et des trémas (Le Goff vs Legoff, Müller vs Muller), et une politique sur les abréviations de prénom (Jean-François vs JF).
Plusieurs choix dans la fonction de fusion méritent d'être discutés avec le métier avant de tourner sur le stock complet. Les champs volatils (email, téléphone, statut d'abonnement) prennent la valeur de la saisie la plus récente. Le nom peut avoir été corrigé par le service client à mi-parcours, donc même règle. La date de création, à l'inverse, doit retomber sur la plus ancienne du groupe : le client existait depuis ce jour-là, quelle que soit la fusion. Le complément d'adresse (BAT A, ESC 2, APPT 305) n'est pas dans la BAN et reste un champ libre côté CRM ; « le plus long gagne » est un défaut raisonnable. Pour l'audit enfin, la liste des id_client fusionnés et un compteur sont le strict minimum : sans ça, vous ne pourrez pas défaire une fusion ratée signalée trois mois plus tard.
Le verdict match_probable ne se fusionne jamais
Le pipeline ne touche jamais automatiquement aux match_probable. C'est une règle ferme. Le verdict signale que l'analyseur de l'API a trouvé un candidat plausible mais avec un doute sémantique : numéro absent, abréviation ambiguë, fragment manquant. Sur de la dédup, ce doute se traduit par un risque de fusion abusive non récupérable (deux clients réels écrasés en un seul, retours postaux d'un côté, perte de l'historique de l'autre).
Le bon réflexe est de pousser ces lignes dans une file de revue exposée à un opérateur. L'interface peut tenir en trois colonnes : la requête initiale, la liste des candidats BAN proposés avec leur id_ban, et un bouton « confirmer / écarter / créer comme nouveau client ». Tant qu'un humain ne tranche pas, l'enregistrement garde un id_ban = NULL et reste hors du périmètre de dédup automatique. Côté volumétrie, c'est typiquement 5 à 15 % du fichier sur des sources hétérogènes, plus sur des bases anciennes. Le détail du calcul du verdict côté API et de l'usage dans un ETL est dans nettoyage d'adresses en Python.
Les pièges terrain qu'on oublie
Les adresses CEDEX n'ont pas de id_ban. Le CEDEX (Courrier d'Entreprise à Distribution Exceptionnelle) est un système de distribution interne à La Poste, pas un point d'adresse géographique. Ces adresses ne figurent pas dans la BAN et l'API les renvoie en no_results ou en match_probable sans identifiant exploitable. Sur un fichier B2B qui mélange adresses postales et CEDEX, isolez les CEDEX en amont (présence du mot dans la ligne, ou code postal en 8 ou 9 si vous avez le détail) et dédoublonnez-les par une clé code_postal + raison_sociale. La validation postale au sens de la norme Afnor sort du périmètre de TrustyData et relève d'un prestataire RNVP, comme couvert dans référentiels RNVP et validation postale.
Deuxième piège, le complément d'adresse n'entre pas dans le id_ban. Tous les habitants d'un même immeuble partagent le même id_ban. Sur un fichier B2C avec une clé id_ban + nom + prenom, deux foyers du même nom dans le même immeuble (un père et son fils par exemple) fusionnent à tort. La parade est d'ajouter le complément à la clé, après normalisation (majuscules, suppression des espaces multiples, équivalences APP/APPT/APT, extraction du numéro d'appartement). Sur un fichier B2B où plusieurs sociétés partagent le même siège, même logique : la clé devient id_ban + raison_sociale_normalisée, et le complément (Bureau 312) peut servir de discriminant supplémentaire si les raisons sociales sont proches.
Autre cas qui mord en production, les voies renommées créent des id_ban orphelins. Quand une voie est renommée ou qu'un numéro est recréé, la BAN attribue un nouvel identifiant. Un fichier validé il y a deux ans peut donc référencer des id_ban qui ne pointent plus sur rien dans le millésime courant. La BAN ne gère pas de redirection, l'API non plus. La parade est de revalider périodiquement (mensuel pour un fichier marketing actif, trimestriel pour un référentiel client moins volatil) et de stocker à côté du id_ban la date de dernière validation. Les lignes qui dépassent un certain âge passent en file de re-validation avant toute opération de dédup ultérieure.
Dernier point pour Paris, Lyon et Marseille : l'API renvoie le code_insee de l'arrondissement (75108 pour le 8e parisien, pas 75056 pour Paris entier). Si vous croisez id_ban avec un champ commune saisi librement, attention à ne pas filtrer sur le mauvais niveau. Le id_ban reste le bon discriminant à lui seul, le code_insee sert à enrichir, pas à dédoublonner.
Ce qu'il faut tracer en base
La dédup tourne en continu sur la durée de vie du fichier, pas en one-shot. Pour que le système reste pilotable, trois champs au minimum à côté du id_ban en base :
id_ban_date_validation(date) : quand l'API a renvoyé ceid_banla dernière fois. Sert au déclenchement des revalidations périodiques.id_ban_verdict(texte) :match_exactoumatch_probable, ou vide si jamais validé. Sert à filtrer les périmètres de dédup automatique vs revue.id_ban_fusion_origine(json ou texte) : la liste des id_client fusionnés au moment de la création de la canonique, et la date. Sert à défaire une fusion en cas de réclamation.
Sans ces trois champs, la dédup tourne en aveugle et personne ne peut justifier une décision quand le service client appelle. C'est le prix de trois colonnes à ajouter en migration.
Pour résumer
On ne dédoublonne pas des adresses, on dédoublonne des personnes ou des entreprises. L'adresse normalisée n'est qu'une composante de la clé, à côté du nom et du prénom en B2C ou de la raison sociale en B2B. C'est aussi presque toujours par cette composante que la dédup naïve plante, parce que les chaînes brutes et les coordonnées GPS varient trop pour être comparées en l'état.
Le id_ban ramène cette composante à une égalité stricte sur un identifiant stable, attribué par l'IGN à chaque point de la BAN. L'API TrustyData l'expose dès le plan Discovery sur POST /address/verify, donc l'approche se prototype sur un échantillon avant d'industrialiser.
La règle de fusion qui tient sur la durée est simple : seul match_exact se dédoublonne automatiquement, les match_probable partent en file de revue, et chaque fusion est tracée pour rester réversible. Les pièges restants (CEDEX hors-BAN, complément d'adresse à intégrer à la clé en habitat collectif, voies renommées qui invalident d'anciens id_ban) se traitent en amont ou par enrichissement de la clé composite.
Pour tester sans intégration, la démo /address/verify renvoie le id_ban directement. Le détail des plans est sur la page tarifs.