Avant d'ouvrir un commerce ou de lancer une tournée de livraison, il faut savoir d'où viendront vos clients. C'est tout le sujet de la zone de chalandise. La bonne nouvelle, c'est qu'en France les données publiques (INSEE, BAN, IRIS) sont aujourd'hui assez fines pour la calculer sans passer par Google Maps ou un outil propriétaire. Voici comment je m'y prends, avec quelques exemples Python qui s'appuient sur l'API TrustyData.
Qu'est-ce qu'une zone de chalandise ?
Définition
Une zone de chalandise, c'est l'aire géographique d'où vient la majorité des clients d'un commerce. Le mot vient de "chaland", l'acheteur régulier. On s'en sert pour calculer un taux de pénétration sur un secteur, bâtir un business plan, ou trancher entre deux emplacements avant une ouverture.
Dans une étude concurrentielle, elle sert aussi à voir où les enseignes se marchent sur les pieds. Avec QGIS, ArcGIS ou Smappen, on visualise vite ces contours et les distances aux concurrents.
Primaire, secondaire, tertiaire
La zone primaire, ce sont les clients les plus proches. C'est elle qui fait l'essentiel du chiffre d'affaires. La secondaire regroupe des clients réguliers mais plus éloignés. La tertiaire, c'est la fréquentation occasionnelle, celle qu'on n'attire qu'un samedi sur deux. La frontière entre les trois dépend de la distance, du temps de trajet et de la densité de population autour du point de vente.
Chalandise vs influence
La zone de chalandise s'appuie sur des faits : adresses de clients, tickets, déplacements. La zone d'influence est plus marketing, elle décrit la notoriété, pas la captation réelle. On peut les rapprocher avec le modèle de Huff, qui simule la probabilité qu'un client choisisse un commerce plutôt qu'un autre selon la distance et l'attractivité.
Comment la calculer
Le rayon kilométrique
La méthode la plus simple : un cercle de 5, 10 ou 15 km autour du point de vente. Ça marche pour une première estimation ou pour une livraison locale. Le défaut, vous le voyez venir : on ignore les obstacles (fleuves, autoroutes, zones non habitées) et on suppose que tous les habitants ont la même probabilité de venir. Ce n'est pas le cas.
La zone isochrone
Plus réaliste, la zone isochrone se base sur le temps de trajet. On affiche tout ce qui est atteignable en 5, 10 ou 20 minutes en voiture. Des outils comme Isocarto ou Smappen le font en quelques clics, et plusieurs moteurs open source (OSRM, Valhalla) exposent le calcul via API. Pour un magasin de centre-ville où la circulation varie d'un quartier à l'autre, c'est nettement plus fidèle qu'un simple rayon.
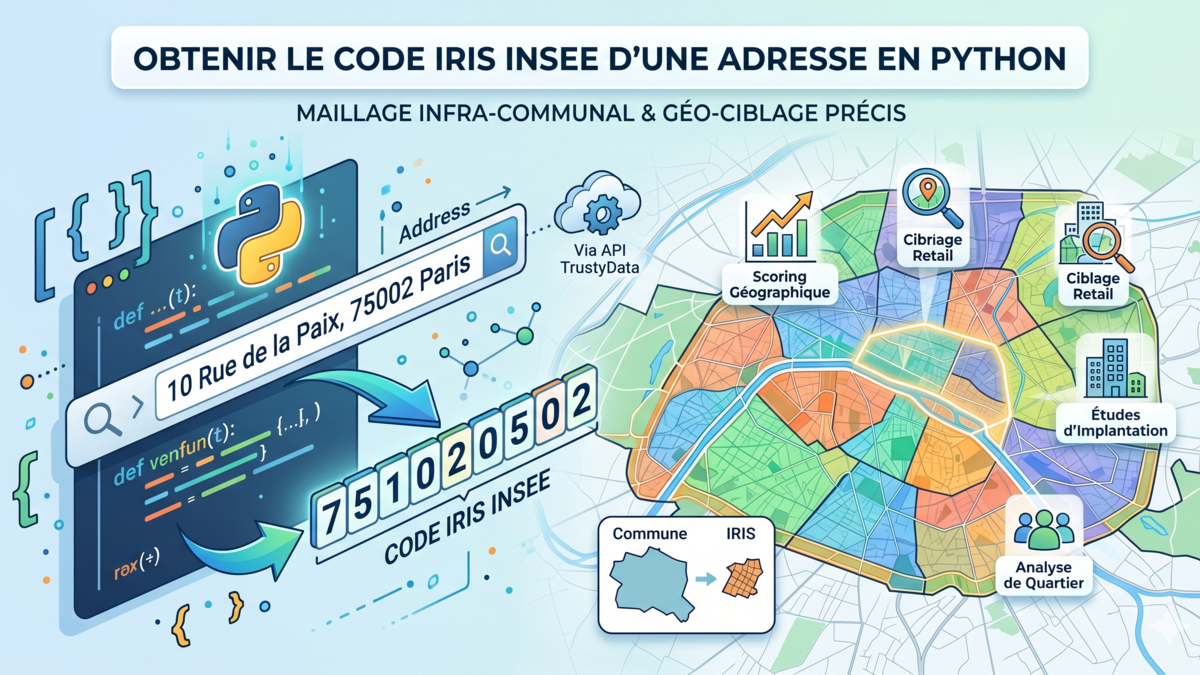
IRIS et carroyage INSEE
C'est l'approche la plus précise. Les zones IRIS regroupent environ 2 000 habitants chacune, avec des données socio-démographiques détaillées : revenus, âge, taille des ménages. Le carroyage INSEE descend à 200 mètres. En croisant un IRIS avec une zone isochrone, vous avez à la fois la géographie réelle et le profil de la population. C'est la base d'un modèle de Huff qui tient la route.
Données et outils en France
Les référentiels open data
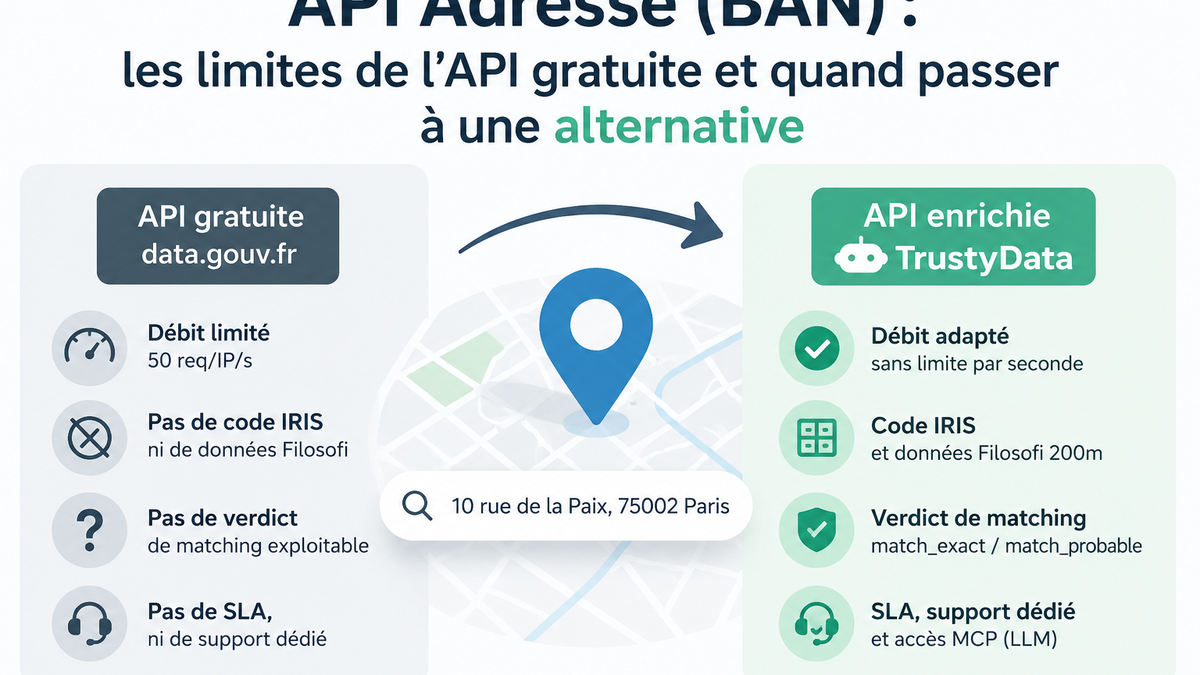
Les données INSEE, la Base Adresse Nationale (BAN) et les fichiers IRIS forment le socle officiel. Ils sont mis à jour régulièrement et accessibles librement. Plusieurs outils les exploitent : QGIS pour ceux qui veulent tout maîtriser, Smappen pour la cartographie clé-en-main, et TrustyData pour ceux qui ont besoin d'une API à intégrer dans un script ou un pipeline ETL.
Pourquoi l'open data plutôt qu'un outil global
Vous n'êtes pas dépendant de Google Maps, dont la tarification et les conditions d'usage peuvent changer du jour au lendemain. Vous gardez la main sur les données, et vous pouvez auditer les résultats — ce qui devient compliqué quand le calcul vit dans une boîte noire.
Limites des solutions génériques
Beaucoup d'outils internationaux se contentent d'un rayon à vol d'oiseau et ne connaissent pas le découpage IRIS. Pour une étude française sérieuse, il faut quelque chose qui parle la langue de l'INSEE.
Calculer une zone avec l'API TrustyData
Géocoder le point d'origine
À partir d'une adresse, TrustyData renvoie les coordonnées GPS et le code IRIS correspondant. C'est le point de départ pour tracer un rayon, requêter un service d'isochrone tiers (OSRM, Valhalla), ou chercher les adresses voisines.
Chercher les adresses dans un rayon
L'endpoint /address/nearby renvoie toutes les adresses BAN dans un rayon donné autour d'un point GPS, triées par distance.
import requests
response = requests.get(
"https://api.trustydata.app/services/v1/address/nearby",
params={"lat": 48.8566, "lon": 2.3522, "radius": 5},
headers={"Authorization": "Bearer VOTRE_CLE_API"},
)
results = response.json()
print(len(results))
Enrichir avec les données IRIS
Chaque adresse trouvée peut être enrichie avec les revenus médians, la composition des ménages et les tranches d'âge issus du référentiel Filosofi. Ces variables alimentent ensuite un modèle de Huff, ou simplement un tableau de bord.
Exemple Python : export GeoJSON
Une fois les adresses récupérées, on peut les charger directement dans un SIG open source :
import geopandas as gpd
zones = gpd.GeoDataFrame(
results,
geometry=gpd.points_from_xy(
[r["lon"] for r in results],
[r["lat"] for r in results],
),
crs="EPSG:4326",
)
zones.to_file("zone_chalandise.geojson", driver="GeoJSON")
On importe ensuite le fichier dans QGIS pour visualiser la cartographie concurrentielle, filtrer selon les flux de mobilité et simuler plusieurs scénarios d'étude de marché.
Interpréter et exploiter les résultats
Une fois les zones tracées et croisées avec les IRIS, on peut estimer le potentiel commercial, repérer les secteurs où le taux de pénétration est faible, et arbitrer entre plusieurs emplacements. Pour un retailer, le même travail sert à adapter les tournées de livraison ou à décider d'ouvrir un point de retrait dans tel quartier plutôt qu'un autre.
L'intérêt de tout automatiser, c'est de pouvoir relancer le calcul chaque trimestre quand les ventes ou la concurrence bougent. Refaire l'étude à la main une fois par an, c'est déjà la moitié du temps perdue.
Prêt à intégrer l'API TrustyData ?
Pour conclure
L'open data a rendu accessible une étude que seuls les grands groupes pouvaient se payer il y a dix ans. Quelques scripts Python, les référentiels IRIS et un QGIS suffisent. TrustyData regroupe ces briques pour ceux qui préfèrent une API à l'assemblage manuel — à vous de voir ce que vous gagnez à coder vous-même.